Introducción a R & Rstudio

Tabla de contenido
¿Qué es? #
R es un lenguaje de programación utilizado principalmente para la estadística computacional.
- Origen: R fue desarrollado principalmente como un lenguaje para el análisis estadístico y contiene una amplia variedad de funciones y paquetes para estadísticas tradicionales y modernas.
- Visualización de Datos: Con paquetes como ggplot2, R permite crear visualizaciones de datos sofisticadas y personalizables.
- Lenguaje de Programación: Aunque R se centra en el análisis de datos, es un lenguaje de programación completo, lo que significa que puedes escribir programas, funciones y paquetes desde cero.
- Paquetes y Extensibilidad: Una de las grandes fortalezas de R es su ecosistema de paquetes. Hay miles de paquetes disponibles para una variedad de aplicaciones, desde análisis de datos biológicos hasta aprendizaje automático.
- Comunidad Activa: R cuenta con una comunidad mundial activa que contribuye constantemente con nuevos paquetes, tutoriales y soluciones a problemas comunes.
- Integración: R se integra bien con otros lenguajes y herramientas. Por ejemplo, puede ser llamado desde Python, conectarse a bases de datos SQL, y mucho más.
- Open Source: R es software libre, lo que significa que es gratuito y su código fuente es accesible para cualquiera que quiera verlo o modificarlo.
¿En qué se diferencia con Rstudio? #
Mientras que R corresponde al lenguaje de programación, Rstudio es una de las opciones de software que nos ayudará a utilizarlo. La diferencia entre uno y otro es similar a la diferencia entre la matemática y la calculadora. Si quisiéramos utilizar R de forma directa podemos abrir el terminal. IDEs alternativos a Rstudio son Visual Studio Code, Google Colab y Jupyter Notebook o Jupyter Lab.
| R | Rstudio |
|---|---|
| Lenguaje de Programación | IDE (Entorno de Desarrollo Integrado) |
| Conjunto formal de instrucciones para comunicarse con computadoras. | Software con herramientas integradas para facilitar el desarrollo de programas. |
| Independiente: Puede ser utilizado con o sin un IDE. | Dependiente del lenguaje: Algunos son específicos para un lenguaje, otros soportan múltiples lenguajes. |
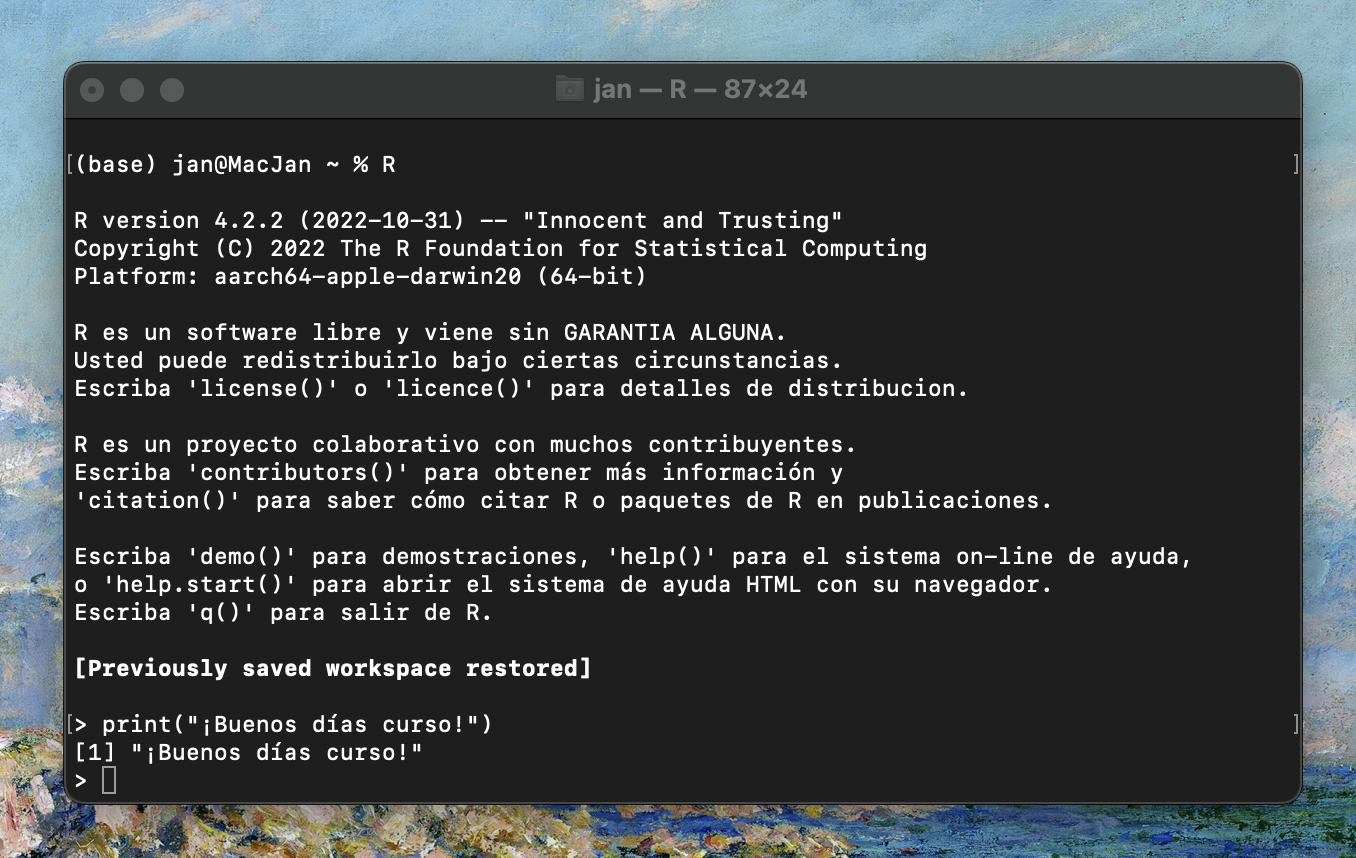
|
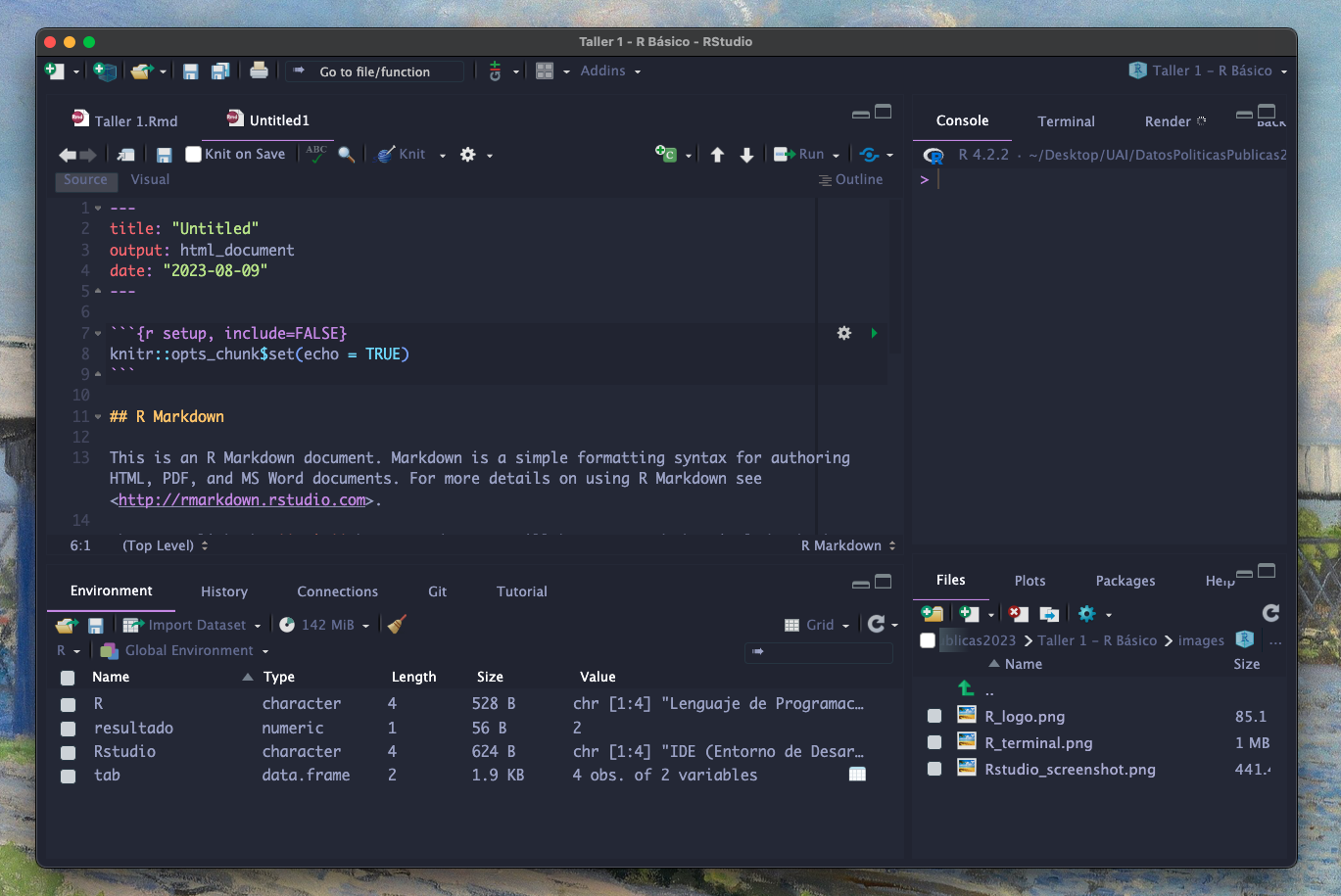
|
¿Por qué preferir R a SPSS o Excel? #
Licencias #
Existen varias razones, pero la más inmediata es que, a diferencia de R, SPSS y Excel son softwares de pago por lo que necesitaremos contar con una licencia en nuestro computador o espacio de trabajo.
Código abierto #
En línea del punto anterior, además de existir una barrera de pago entre los programas, también está presente el hecho de que R es un software de código abierto al que cualquier usuario puede tener acceso. Esto permite que cualquiera pueda estudiar el código, desarrollar complementos y reparar sus problemas. El que exista una comunidad activa de usuarios trabajando en torno al lenguaje tiene por ventaja que rápidamente encontrarás las novedades disponibles como paquetes (ej. Chat GPT).
Volumen de datos #
“Concretamente, según apunta The Daily Mail, el problema se encontraría en la tabla de Excel que los oficiales usan para registrar los casos y generar las cifras que se hacen públicas en los informes diarios.
Microsoft Excel, el programa de hojas de cálculo más famoso del mundo, tiene ciertas limitaciones en los archivos que genera; concretamente, las hojas de datos de Excel no pueden superar las 16.384 columnas y las 1.048.576 filas.”
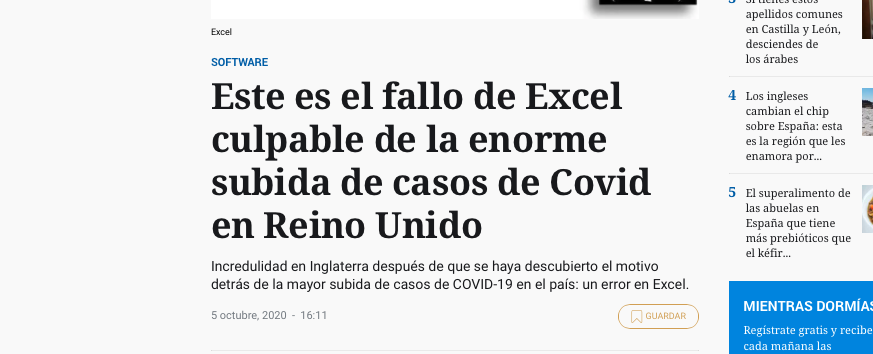
R está diseñado para trabajar
con grandes volúmenes de datos de manera eficiente. Puede
cargar y procesar conjuntos de datos muy grandes gracias a
su capacidad de trabajar con matrices y operaciones
vectorizadas. Ofrece la posibilidad de realizar cálculos en
paralelo y aprovechar la potencia de múltiples núcleos de
CPU, lo que acelera el procesamiento de datos. Además, R
cuenta con paquetes y librerías específicas para
optimización de rendimiento en el manejo de grandes datos.
Además, permite realizar manipulaciones y transformaciones
de datos complejas y específicas de manera más eficiente,
gracias a su enfoque en la programación y al uso de paquetes
especializados como dplyr y tidyr.
Versatilidad #
Una de las ventajas más destacadas de R en comparación con programas como SPSS y Excel es su asombrosa versatilidad de usos. Mientras que SPSS y Excel tienden a estar más orientados hacia análisis específicos y tareas limitadas, R se erige como un lenguaje de programación estadística con una amplia gama de aplicaciones. Desde análisis de datos, modelado estadístico y visualización hasta minería de datos, aprendizaje automático y bioinformática, R se adapta a prácticamente cualquier dominio en el que se requiera manipulación y análisis de datos. Esta versatilidad es posible gracias a la vasta cantidad de librerías disponibles, cada uno diseñado para abordar desafíos específicos. Como resultado, R se convierte en una herramienta poderosa y adaptable para profesionales y científicos de datos que buscan realizar análisis complejos y personalizados en una variedad de contextos y disciplinas.

Conceptos básicos #
Consola #
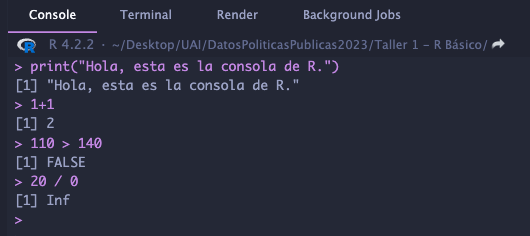
La consola de RStudio cumple la función de ser la interlocutora con el lenguaje R. En ella puedes dar instrucciones instrucciones al programa. Puedes hacer cálculos, analizar datos y probar cosas. Cuando escribes algo y presionas Enter, el programa te muestra los resultados. También, si algo sale mal, te ayuda a entender qué pasó mal para poder arreglarlo.
Aunque se vea compleja, la consola de R siempre está dispuesta a ayudarte.

Ejemplo de interacción con la consola #
Aquí hay un resumen de operaciones básicas que puedes realizar en R:
# Operaciones aritméticas
5 + 3
10 - 2
4 * 6
20 / 5
2^3
sqrt(25)
15 %% 4
# Operaciones booleanas
TRUE & FALSE
TRUE | FALSE
!TRUE
# Otros ejercicios básicos
10 > 5
6 == 6
8 != 7
# 8
# 8
# 24
# 4
# 8
# 5
# 3
# FALSE
# TRUE
# FALSE
# TRUE
# TRUE
# TRUE
El comando ! implica una negación de términos booleanos.
!FALSE
## [1] TRUE
!TRUE
## [1] FALSE
Hasta ahora todo lo que hemos visto han sido cálculos “en el
aire”. R es un lenguaje de programación orientado a objetos,
lo que quiere decir que estaremos constantemente creándolos
para trabajar con ellos. Para crear un objeto usaremos <-,
acción que llamaremos asignar. Veamos un ejemplo:
Numero_bipedos <- 5
Numero_cuadripedos <- 7
Numero_total_de_patas <- (Numero_bipedos * 2) + (Numero_cuadripedos * 4)
Numero_total_de_patas
## [1] 38
Nota: Se considera una buena práctica evitar el uso de tildes en la creación de objetos. De este modo se evitan problemas de compatibilidad al pasar de un sistema operativo a otro.
Source o Scripts #
Resultaría tedioso si tuviéramos que estar digitando nuestro
código cada vez desde 0. Por esta razón, utilizamos
scripts: archivos de texto que contienen la sintaxis de
nuestro código. De este modo podemos ejecutarlo todo de una
vez, ir añadiendo más líneas o reparando errores. En Rstudio
los scripts se encuentran en el panel Source ubicado
(normalmente) en la esquina superior izquierda.
Los archivos de scripts de R tienen por formato .R, así
podemos tener el archivo Ejemplo.R almacenado en nuestro
computador. Existen otros formatos de trabajo e incluso
podríamos utilizar como base un archivo .txt si
seleccionamos manualmente que corresponde a un código de
R.
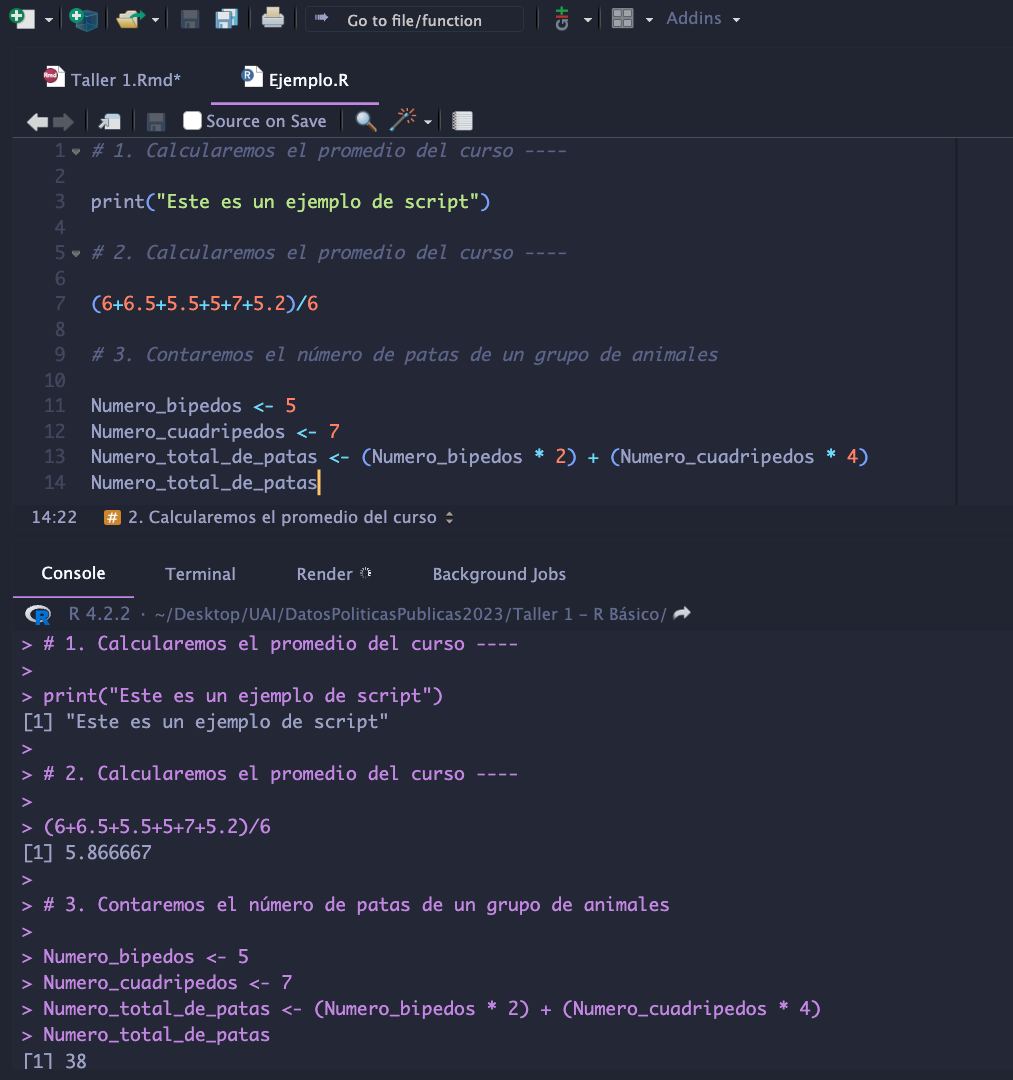
Funciones #
Las funciones son utilizadas para realizar cálculos o modificar datos en la plataforma. En lugar de tener que programarlas manualmente podemos usarlas para ahorrarnos trabajo. Una función tiene normalmente esta estructura:
funcion(objeto, argumento1 = "valor 1", argumento2 = "valor 2"...)
Por ejemplo, podemos redondear \(\pi\):
pi
## [1] 3.141593
round(pi,digits = 2)
## [1] 3.14
Muy frecuentemente desconoceremos cómo usar una función. En
estos casos utilizaremos ? antes de la función para llamar
al menú de ayuda. Por ejemplo, al ejecutar ?round() se
mostrará esto en el programa:
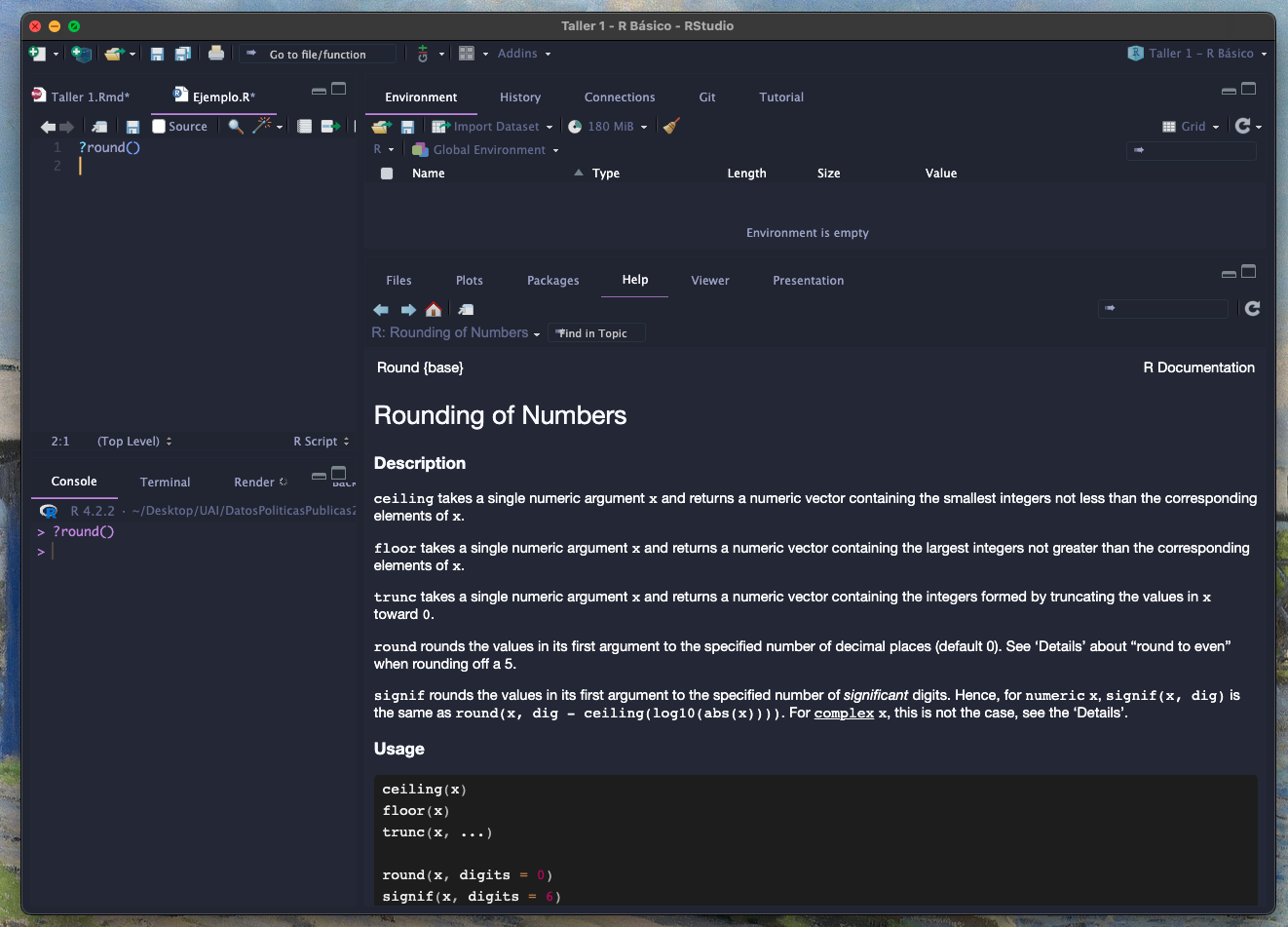
Tipos de objetos #
En R encontraremos de diferentes tipos. Podemos esquematizar a la mayoría en 4 niveles:
1. Objetos de valores únicos #
Estos pueden ser booleanos, numéricos, texto, etc.
objeto <- "Hola!"
objeto
## [1] "Hola!"
2. Vectores #
Son cadenas de valores de un mismo tipo. Utilizamos c() (de concatenar) para unir valores únicos en un mismo objeto.
vector <- c(1,2,3,4)
vector
## [1] 1 2 3 4
3. Datasets #
Son la acumulación de vectores en formato de columnas.
Aunque existen varios tipos el más común es data.frame.
Siempre son de un formato rectangular.
dataset <- data.frame(Columna1= c(1,2,3,4), Columna2 = c("Rojo","Verde","Negro","Blanco"))
dataset
## Columna1 Columna2
## 1 1 Rojo
## 2 2 Verde
## 3 3 Negro
## 4 4 Blanco
4. Listas #
Corresponden a los más complejos pues permiten anidar objetos de distinta naturaleza y a múltiples niveles. En el uso básico son poco usadas.
lista <- list(objeto,vector,dataset)
lista
## [[1]]
## [1] "Hola!"
##
## [[2]]
## [1] 1 2 3 4
##
## [[3]]
## Columna1 Columna2
## 1 1 Rojo
## 2 2 Verde
## 3 3 Negro
## 4 4 Blanco
Indexación #
En todos los tipos de objetos encontraremos indexación que
nos permite identificar o extraer datos en específico. En
cadenas de valores usamos el formato objeto[índice]. Por
ejemplo:
nombres <- c("Juan","Camila","Diego","Agustina")
nombres[3]
## [1] "Diego"
A través de la indexación podemos obtener más de un valor:
nuevo_vector <- nombres[1:3]
nuevo_vector
## [1] "Juan" "Camila" "Diego"
nuevo_vector <- nombres[c(1,4)]
nuevo_vector
## [1] "Juan" "Agustina"
La indexación para datasets adquiere el formato
objeto[fila,columna]. Así, por ejemplo:
dataset[1,2]
## [1] "Rojo"
También podemos indicar el nombre de una de las columnas del dataset:
dataset[1,"Columna2"]
## [1] "Rojo"
Podemos omitir la coma si queremos extraer directamente una columna. Por ej.:
dataset["Columna2"]
## Columna2
## 1 Rojo
## 2 Verde
## 3 Negro
## 4 Blanco
Si queremos extraer una fila podemos omitir el valor de columna. Por ej.:
dataset[1,]
## Columna1 Columna2
## 1 1 Rojo
Por último, para la indexación de listas usamos este formato
lista[[indice de lista]][indice del objeto]
# El tercer elemento de la lista que creamos es nuestro dataset.
lista[[3]][2,2]
## [1] "Verde"
Librerías #
Probablemente hayan jugado a “Los Sims”. La mejor forma de explicar lo que es una librería de R es asimilarla a una extensión del juego. Si quiero usar la extensión ‘Día de campo’ debemos instalarla y cargarla.

Con la función install.packages() podemos instalar todas
las librerías que queramos (es parte de la ventaja de R no
tener que pagar por ellas). Es importante utilizar comillas
para nombrarlas, por ej.:
install.packages("dyplr")
Cada librería basta instalarla una vez. Si volvemos a
ejecutar el comando se instalará nuevamente o ,si es que no
lo hacemos hace tiempo, se actualizará. Si tienes un código
que requiera instalar librerías déjalas comentadas, es
decir, poner un # al comienzo de la línea para evitar que
se ejecute.
Para cargar la librería usamos la función library(). A
diferencia de la instalación, es importante cargar la
librería al inicio de la sesión cada vez que necesitemos
usarla. Al empezar a aprender es común que se nos olvide y
recibamos este error:
frq(cars)
En R los errores usualmente nos indican qué es lo que está fallando. Si la consola nos dice que no encuentra la función es porque no se ha cargado o porque la escribimos mal (muy común al principio).
R es sensible a las mayúsculas. El objeto dataset es
distinto de Dataset. La función Frq() es distinta de
frq().
library(sjmisc)
Frq(cars)
# La función correcta es frq()
Algunas librerías #
-
Base y stats: Son parte del paquete base de R y proporcionan muchas funciones esenciales para el análisis y manipulación de datos.
-
Tidyverse: No es una sola librería, sino una colección de paquetes.
-
Ggplot2: Para la creación de gráficos avanzados.
-
Dplyr: Manipulación de datos.
-
Tidyr: Herramientas para cambiar el formato de datos.
-
Readr: Lectura y escritura de datos.
-
Tibble: Moderna representación de data frames.
-
Stringr: Manipulación de cadenas de texto.
-
Lubridate: Manipulación de fechas y horas.
-
Cme4: Utilizado para modelos lineales mixtos.
-
Car: Funciones y datasets para complementar el libro “Companion to Applied Regression”.
-
Forecast: Métodos y herramientas para la predicción de series temporales.
-
Rmarkdown: Herramientas para convertir archivos de R Markdown en documentos formativos.
-
Shiny: Creación de aplicaciones web interactivas directamente desde R.
-
Data.table: Manipulación de datos de forma rápida y eficiente.